Netlify で submodule (private repo) を使用する
概要
- Netlify で private submodule を使用する
詳細
private な submodule はエラーになる
当たり前といえば当たり前だが...
権限不足で submodule update --init に失敗する
Netlify 側で Deploy Key を発行する
- Netlify Project を開く
- Deploy Settings を開く
- Build & deploy -> Continuous Deployment -> Deploy key
- Generate public deploy key
で、SSH Key を発行する
GitHub Repository に設定する
- Submodule の Repository を開く
- Settings -> Security -> Deploy keys
- Add deploy key を設定
Nuxt.js x Class API x Storybook (x SCSS)
前提・環境
$ node -v v14.17.3 $ npm -v 7.19.1 $ yarn -v 1.22.10 $ nuxt -v @nuxt/cli v2.15.8
- Nuxt.js x TypeScript x Class API のプロジェクトが用意されていること
Class API の Nuxt.js で Storybook を使ってみる
まずはデフォルトで動作確認
1. まずは https://storybook.js.org/docs/react/get-started/install に従って Storybook をインストール
$ npx sb init
2. デフォルト状態で動作確認
$ yarn storybook
3. 問題ないことを確認
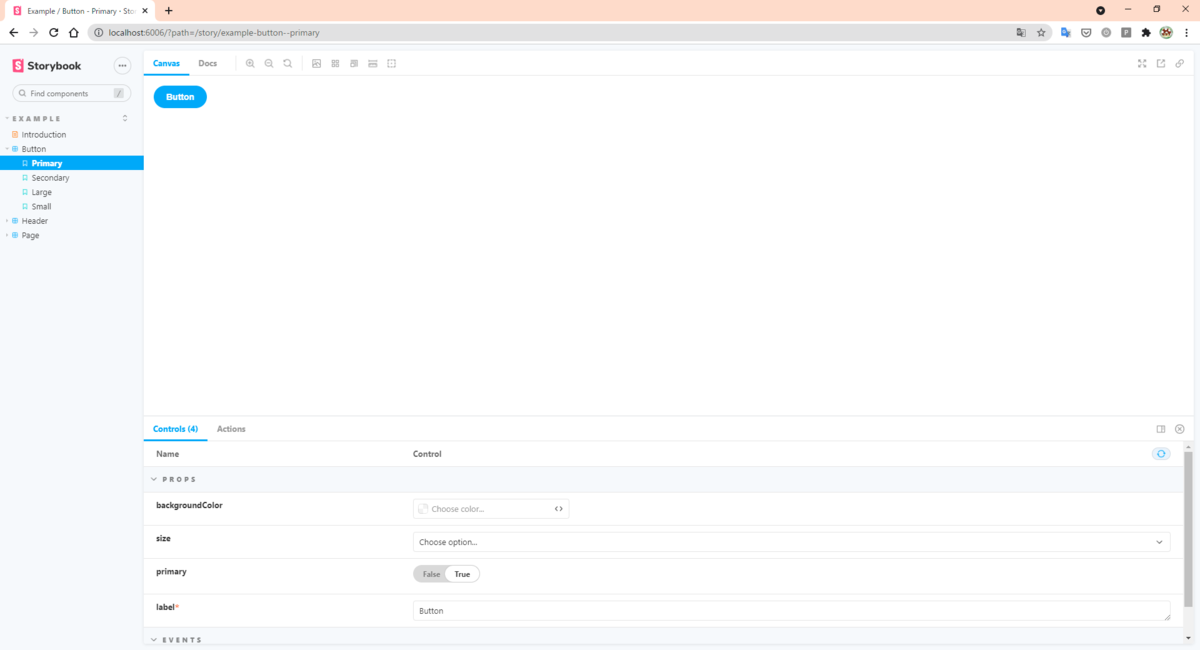
まぁ。。。Options API の例だし、できるよね。
続いて、↑ で生成された Vue ファイルを Class API 向けに編集する
1. 編集作業
// ./stories/Button.vue
<template>
<button type="button" :class="classes" @click="onClick" :style="style">{{ label }}</button>
</template>
- <script>
- import './button.css';
+ <script lang="ts">
+ import { Vue, Component, Prop } from 'vue-property-decorator'
- export default {
- name: 'my-button',
+ @Component
+ export default class Input extends Vue {
- props: {
- label: {
- type: String,
- required: true,
- },
- primary: {
- type: Boolean,
- default: false,
- },
- size: {
- type: String,
- default: 'medium',
- validator: function (value) {
- return ['small', 'medium', 'large'].indexOf(value) !== -1;
- },
- },
- backgroundColor: {
- type: String,
- },
- },
+ @Prop({ type: String, required: true })
+ private readonly label!: string
+ @Prop({ type: Boolean, default: false })
+ private readonly primary!: boolean
+ @Prop({
+ type: String,
+ default: 'medium',
+ validator: (value) => {
+ return ['small', 'medium', 'large'].indexOf(value) !== -1
+ },
+ })
+ private readonly size!: string
+ @Prop({ type: String })
+ private readonly backgroundColor!: string
- computed: {
- classes() {
- return {
- 'storybook-button': true,
- 'storybook-button--primary': this.primary,
- 'storybook-button--secondary': !this.primary,
- [`storybook-button--${this.size}`]: true,
- };
- },
- style() {
- return {
- backgroundColor: this.backgroundColor,
- };
- },
- },
+ private get classes() {
+ return {
+ 'storybook-button': true,
+ 'storybook-button--primary': this.primary,
+ 'storybook-button--secondary': !this.primary,
+ [`storybook-button--${this.size}`]: true,
+ }
+ }
+ private get style() {
+ return {
+ backgroundColor: this.backgroundColor,
+ }
+ }
- methods: {
- onClick() {
- this.$emit('onClick');
- },
- },
+ private onClick() {
+ this.$emit('onClick')
+ }
- };
+ }
</script>
+ <style scoped>
+ .storybook-button {
+ font-family: 'Nunito Sans', 'Helvetica Neue', Helvetica, Arial, sans-serif;
+ font-weight: 700;
+ border: 0;
+ border-radius: 3em;
+ cursor: pointer;
+ display: inline-block;
+ line-height: 1;
+ }
+ .storybook-button--primary {
+ color: white;
+ background-color: #1ea7fd;
+ }
+ .storybook-button--secondary {
+ color: #333;
+ background-color: transparent;
+ box-shadow: rgba(0, 0, 0, 0.15) 0px 0px 0px 1px inset;
+ }
+ .storybook-button--small {
+ font-size: 12px;
+ padding: 10px 16px;
+ }
+ .storybook-button--medium {
+ font-size: 14px;
+ padding: 11px 20px;
+ }
+ .storybook-button--large {
+ font-size: 16px;
+ padding: 12px 24px;
+ }
+ </style>
2. そして動作確認!
$ yarn storybook
問題なく行ける!!
この調子で SCSS もやってしまえ!
Style を SCSS にする
1. 編集作業
// ./stories/Button.vue - <style scoped> + <style lang="scss" scoped>
2. 動作確認
$ yarn storybook ERROR in ./stories/Button.vue?vue&type=style&index=0&id=43fc969c&lang=scss&scoped=true& (./node_modules/vue-docgen-loader/lib??ref--12!./node_modules/vue-loader/lib??vue-loader-options!./stories/Button.vue?vue&type=style&index=0&id=43fc969c&lang=scss&scoped=true&) 49:0 Module parse failed: Unexpected token (49:0) File was processed with these loaders: * ./node_modules/vue-docgen-loader/lib/index.js * ./node_modules/vue-docgen-loader/lib/index.js * ./node_modules/vue-loader/lib/index.js You may need an additional loader to handle the result of these loaders.
- ここに来て、エラー!
3. ということでググる
- https://storybook.js.org/docs/react/configure/webpack#extending-storybooks-webpack-config
- どうやら、SCSS を使うときは Webpack Config をいじってね。とのことらしい。
ということでいじる
// ./.storybook/main.jsmain.js + const path = require('path'); module.exports = { "stories": [ "../stories/**/*.stories.mdx", "../stories/**/*.stories.@(js|jsx|ts|tsx)" ], "addons": [ "@storybook/addon-links", "@storybook/addon-essentials" - ] + ], + webpackFinal: async (config, { configType }) => { + // `configType` has a value of 'DEVELOPMENT' or 'PRODUCTION' + // You can change the configuration based on that. + // 'PRODUCTION' is used when building the static version of storybook. + + // Make whatever fine-grained changes you need + config.module.rules.push({ + test: /\.scss$/, + use: ['style-loader', 'css-loader', 'sass-loader'], + include: path.resolve(__dirname, '../'), + }); + + // Return the altered config + return config; + }, }
4. 動作確認
$ yarn storybook
いけた!
assets/scss/styles.scss に定義してある変数を使ってみる
1. Vue ファイルの編集作業
// ./stories/Button.vue
.storybook-button--primary {
- color: white;
- background-color: #1ea7fd;
+ color: $color_light;
+ background-color: $color_primary;
}
2. 動作確認
$ yarn storybook ERROR in ./stories/Button.vue?vue&type=style&index=0&id=43fc969c&lang=scss&scoped=true& (./node_modules/css-loader/dist/cjs.js!./node_modules/vue-loader/lib/loaders/stylePostLoader.js!./node_modules/sass-loader/dist/cjs.js!./node_modules/vue-loader/lib??vue-loader-options!./stories/Button.vue?vue&type=style&index=0&id=43fc969c&lang=scss&scoped=true&) Module build failed (from ./node_modules/sass-loader/dist/cjs.js): SassError: Undefined variable. ╷ 59 │ color: $color_light; │ ^^^^^^^^^^^^
3. Storybook の設定周り編集作業
// ./.storybook/main.js
config.module.rules.push({
test: /\.scss$/,
- use: ['style-loader', 'css-loader', 'sass-loader'],
+ use: [
+ 'style-loader',
+ 'css-loader',
+ 'sass-loader',
+ {
+ loader: 'sass-resources-loader',
+ options: {
+ resources: ['assets/scss/styles.scss'],
+ },
+ },
+ ],
include: path.resolve(__dirname, '../'),
})
4. 動作確認
$ yarn storybook
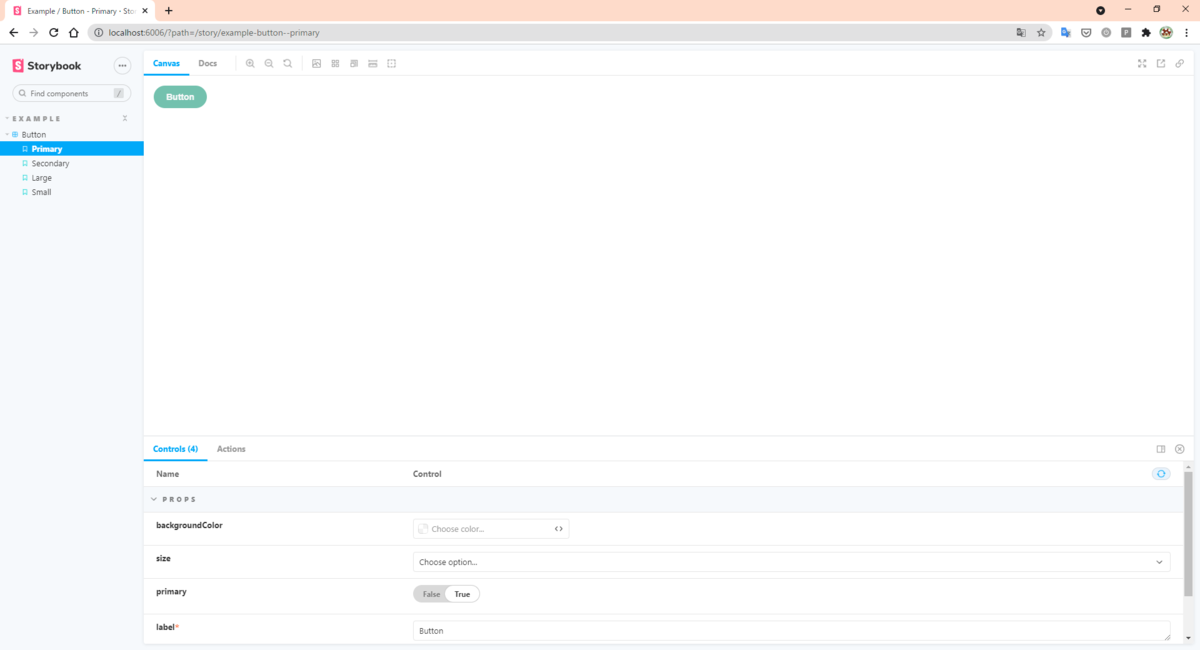
最後に
- Storybook をインストールしたことで、
yarn dev実行時に CSS-Loader 周りにエラーが出る yarn add -D css-loader@4.2.0とバージョン指定することで解決できる
yarn dev と yarn storybook 別々のビルドになるので、両方確認しなきゃいけないことがわかった。



Blender 2.93.1 で mmd_tools をインストールする
この記事のキッカケ
- .pmx ファイルを読み込みたかった
- しかし、インポートに MMD が出てこなかった
環境
やったこと
- blender_mmd_tools を zip でダウンロード
- zip を解凍して
mmd_toolsフォルダを Blender addons にコピペ${BLENDER_ROOT}/2.93/scripts/addons/にコピペした
- Blender 起動
- File -> Import を確認
実際
- MMD が無かった!
期待値
- MMD の形式がインポートできること
解決策
Edit -> PreferencesからAdd-onsを選択してmmdで検索- Object: mmd_tools を有効にする必要があった
Blender Beginner Tutorial の復習 (後半)
@startmindmap Blender_Beginner_Tutorial
title "Blender Beginner Tutorial の復習 (後半)"
<style>
mindmapDiagram {
.red {
BackgroundColor LightPink
}
.green {
BackgroundColor LightGreen
}
.blue {
BackgroundColor LightBlue
}
}
</style>
+ ドーナツチュートリアル
++ Part_3
+++ 3-1: Modelling
++++ コーヒーカップのリファレンス画像を追加する: Shift + A -> Image -> Reference
+++++ リファレンス画像からモデルを作るので向き等を合わせる必要がある
+++++ X軸を中心に回転する: R + X
++++++ Object Properties から Rotation X を変更することで 90 度に変更しても良い
+++++ リファレンス画像のサイズを変更する: S
+++++ リファレンス画像の位置を変更する: G + X
++++ コーヒーカップの元になるメッシュオブジェクトを追加する: Shift + A -> Cylinder
+++++ Radius と Depth を良い感じのサイズにする
++++++ Radius: 0.05m
++++++ Depth: 0.13m
+++++ Verticles も変更するが、デフォルトのままでOK
++++++ Verticles: 32
++++ Cylinder をリファレンス画像のカップに合わせる
++++ Cylinder をリファレンス画像のちょうど中央になるようにする
++++ コーヒーカップの縁にサイズが合うように横幅を大きくする: S + Shift + Z
+++++ 上面は良い感じのサイズになる
++++ 次は底面を整えていく
+++++ 底の頂点を全て選択する: Alt + 左クリック
+++++ スケールを行う: S
+++++ 移動する: G + Z
+++++ X Ray モードでもOK
++++ ループカットして頂点を増やしていく: Ctrl + R
+++++ 取っ手の部分に増やしていくと良い
++++ カットした頂点を底面のようにスケールしていく
++++ カップに穴を開ける
+++++ ソリッドビューモードで上面の頂点を選択
+++++ X -> Faces
++++ カップに厚みを付ける: Modifiers -> Solidify
+++++ Thickness: 2mm
++++ スムーズシェード: 右クリック + Shade Smooth
++++ 更に詳細を追加する: Modifiers -> Subdivision Surface
+++++ Viewport: 2
++++ フチに厚みを付ける
+++++ 更にループカットを増やす
++++ プレーンなメッシュを非表示にすると底が☆になってる
+++++ 底が巨大なフェイスになっているため
+++++ 32 の Verticles が1点に集中しているため
+++++ Edit Mode で I を押してループカットのようにする x2
+++++ 少しスケールして調整しても良い
+++ 3-2: Complete Modeling
++++ 下準備
+++++ 取っ手を作るときにやりやすいように頂点の間を真右にする
+++++ まずは Solidify (Modifires) を適用する
++++ 取っ手を作る
+++++ Face 選択モードにして押し出す面を選択する
+++++ 選択した面を押し出す: E
+++++ もう一度 E を押して R で回転させながら向きを定める
+++++ Vertex 選択モードにしてはみ出た頂点を移動する
+++++ 押し出し、移動を取っ手の90度の位置まで繰り返す
+++++ スピンツールを利用して一気に180度まで
++++++ Shift + 右クリックで中心点を取っ手の中心へ移動する
++++++ 使いづらいけど頑張ると Spin のポップアップが出る
++++++ 軸は 0, -1, 0 にする必要がありそう
++++++ 中心点をちょっとずらせばズレが解消される
++++++ 頂点を移動させる等して調整
+++++ 残りは押し出しの繰り返しで接続直前までやる
+++++ 面を接続
++++++ まずは、面同士を削除する
++++++ Alt + 左クリック で面を選択
++++++ もう一方の面も複数選択
++++++ F3 で bridge と検索して繋げる
+++++ 接続部を微調整
++++++ 接続部の4頂点を選択する
++++++ Shift + E で調整 (押し出しの逆をできるのか?)
++++++ 下側も
++++++ 更に Subdivision Surface の Viewport を増やすとよりキレイになる
+++++++ Viewport は Rendering には関係ないので Render の方のレベルを上げておく
++++ 3Dカーソルをカップの中心へ
+++++ Shift + S -> Cursor to selected
++++ お皿を作る
+++++ Shift + A -> Mesh -> Circle
+++++ Fill Type -> Ngon
+++++ Verticles -> 16
++++ お皿を移動する
+++++ 淵の部分に合わせる
++++ お皿のモデリング
+++++ 面を選択する
+++++ I (Inset Faces)
++++++ ループカットのノリでカップに合わせる
+++++ Ctrl + R (ループカット): 頂点を増やす (2個)
+++++ プロポーショナル編集(Sphere)を使って頂点全体的に操作する
+++++ お皿に厚みを付けるために Solidify を追加する
++++++ 3mm
+++++ Subdivision Surface も追加する
+++++ カップと同様でフチが鋭すぎるのでループカット(Ctrl + R)で落ち着かせる
+++++ Smooth Shade する
+++++ Subdivision Surface の Viewport を増やして Render 状態を確認する
++++ お皿に窪みを付ける
+++++ Inset Faces (I) で突起させるところを作る
++++++ Loop Cut (Ctrl + R) と Inset Faces (I) の違いは何?? <<red>>
+++++ Solidify Modifier を確定
+++++ 一番内側の頂点はカップ底に合わせるようにスケール(S)
+++++ 突起周辺に Loop Cut (Ctrl + R) と Inset Faces (I) を使って滑らかにする
+++ 3-3: Glass and Liquid
++++ 液体のマテリアルを分離して Coffee にする
++++ 液体をコーヒーっぽくする
+++++ Volume -> Volume Absorption
++++++ シェーダーを開くと追加されている
+++++ Volume -> Density を大きくすると黒くなる
+++++ 黄色がかったものから黒くするために Volume Absorption を使っている
+++ 3-4: Realistic Liquid
++++ カップをガラス質にする
+++++ マテリアル追加
++++++ Transmission: 1
++++++ Roughness: 0
++++ お皿にもガラス質を適用する
+++++ カップで追加したマテリアルを利用する
++++++ お皿 -> カップの順番で複数選択
++++++ Ctrl + L -> Link Material
++++ ガラス質の重なった部分が暗くなる問題
+++++ ベースカラーを純粋な「白」にする
++++ カップとお皿を親子にする
+++++ カップ -> お皿の順で複数選択
+++++ Ctrl + P -> Object (Keep Transform)
++++ 液体を作る
+++++ Face 選択モードで内側の面を選択していく
+++++ 最後は頂点選択モードで C を押してブラシ選択する
+++++ Shift + D: 複製
+++++ P -> Selection
+++++ Show Overlays -> Face Orientation
++++++ 赤を青にする...
+++++ いい感じに液体を縮小する
+++++ 表面張力を作る
++++++ 最上辺を拡大したり引っ張ったり
++++++ あまり大きな変化はないけど、細かいところにも気を配る
+++ 3-5: Condensation
++++ UV Unwrappin をサイコロで練習
+++++ Cube を追加する
++++++ Shift + A -> Mesh -> Cube
+++++ Cube は最初から UV Unwrap されているのでリセットする
++++++ U -> Reset
+++++ 自分でカットして UV Unwrap (展開) する
++++++ エッジ選択モードにする
++++++ 上辺の3箇所を選択する
++++++ Ctrl + E -> Mark seam
++++++ U -> Unwrap
++++++ 色々選択する
++++++ Ctrl + E -> Mark seam
++++++ U -> Unwrap
++++ カップを UI Unwrapping する
+++++ 動画の通りに Mark seam と unwrap を繰り返す
+++++ UV Square を使ってカップ側を四角にする
++++++ L でカップ側を選択
++++++ UV Square -> To Grid By Shapea
++++ カップの内側に水滴のテクスチャを反映させる
+++++ カップのマテリアルを追加する
+++++ ガラス属性を継承する
+++++ カップの内側をフェイスモードで選択する
+++++ 新しく作ったマテリアルをアサインする
+++++ 水滴テクスチャを貼るために Shading に移動する
++++++ テクスチャを追加する
+++++++ Shift + A -> Texture -> Image Texture
+++++++ 該当の水滴テクスチャを選択する
+++++++ ImageTexture.Color -> Principled BSDF.Normal
+++++++ 間に Normal Map を入れる
++++++++ Shift + A -> Vector -> Normal Map
+++++++ Image Texutre の Color Space を Non-Color にする
++++++ UV Editing で水滴のサイズを調整する
+++++++ UV Unwrap を拡大すると水滴が小さくなる
-- Part_4
--- 4-1: Composition
--- 4-2: Scene Texturing
--- 4-3: Last Adjustments
--- 4-4: Keyframe Animation
--- 4-5: Rendering
--- 4-6: Compiling the Final
@endmindmap
Blender Beginner Tutorial の復習 (前半)
@startmindmap Blender_Beginner_Tutorial
title "Blender Beginner Tutorial の復習 (前半)"
<style>
mindmapDiagram {
.red {
BackgroundColor #FFBBCC
}
.green {
BackgroundColor lightgreen
}
.blue {
BackgroundColor lightblue
}
}
</style>
+ ドーナツチュートリアル
++ Part_1
+++ 1-1:
+++ 1-2: Modeling
++++ 低解像度のメッシュで作業するほうが簡単
+++++ 依存する頂点が少ないため
+++++ 出来る限り正方形に近い方がいい?
++++ 現実世界は不完全
+++++ 歪みがより本物っぽく見せる
++++ 編集モードはオブジェクトモードで選択したもののみが触れる
++++ 頂点の周辺に影響を与える編集
+++++ プロポーショナル編集: O
+++++ スクロールによって影響を与える範囲を変更することができる
++++ SmoothShade: オブジェクトモードで右クリック
+++++ モデルの形状がスムーズになる
+++++ 但し、頂点数は変わってないのでエッジはシャープのままになっている
++++++ Subdivision Surface (Modifiers) で頂点を増やす
++++ Subdivision Surface (Modifiers)
+++++ エッジをスムーズにする
+++++ Viewport を変えるとより高解像度になる
+++ 1-3: Modifiers
++++ 通常モードだと裏側は選択できない (見えている範囲しか選択ができない)
+++++ X Ray モードにすることでモデルを透明化できる: Alt + Z
++++ モデルの複製: Shift + D
++++ モデルの分離: P -> Selection
+++++ これで複製したモデルが2つに分離する
++++ 繋がる全ての頂点を選択する: Ctrl + L
+++++ このチュートリアルでは分離し忘れ時に役立っていた
++++ サイドメニュー: N
+++++ View -> Clip start
++++++ 拡大時にどこまで近づけるか
++++ Solidify (Modifiers)
+++++ 厚みを付ける
+++++ Offset: 内側に厚みを作るか外側に厚みを作るか
+++++ Thickness: 厚さ
++++ Modifiers は上から順番に適用されていく
+++++ Subdivision Surface -> Solidify だと、厚み部分がシャープになる
+++++ Solidify -> Subdivision Surface だと、厚み部分もスムーズになる
+++ 1-4: Modeling
++++ Modifiers の Edit Mode を OFF にすると編集モードでは Disable になる
++++ Subdivide: 編集モードで全選択 + 右クリック
+++++ メッシュが細かくなる
+++++ Number of Cuts: 細かさを増やせる
+++++ Smoothness: エッジがスムーズになる
++++ エッジ全体を選択: Alt + 左クリック
++++ Invert: Ctrl + I
++++ Hide Selected: H
+++++ Revert Hide Selected: Alt + H
++++ Snap: Shift + Tab <<red>>
+++++ 自動的に接続する機能 <<red>>
++++++ 表面に沿って移動可能 <<red>>
+++++ Face -> Project Individual Elements <<red>>
++++++ 選択していない頂点付近も Snap 対象になる <<red>>
+++++ Icing の垂れ下がりを表現する <<red>>
++++++ 悪い例??? <<red>>
++++ 押し出し: E
+++++ 伸ばすことができる
+++++ Icing の垂れ下がりを表現する
++++++ 良い例???
++++ Splidify -> Edge data -> Crease inner <<red>>
+++++ 内側の辺に重み付けをする?? <<red>>
+++ 1-5: Sculpting
++++ New Collection: M
+++++ 右クリックでコレクションを作ったほうが直感的かも
++++ Modifiers は Apply して初めて適用される
+++++ 適用されるとメッシュが正しく細かくなる
++++ スカルプトモード
+++++ オブジェクトモードで選択中のものが対象になる
+++++ ブラシサイズ変更: F
+++++ Subdivision Surface が適用されていることによって潰しやすくなる
+++++ 筆圧変更: Shift + F
++++ Donut
+++++ Draw ブラシ: 表面を凸凹に
+++++ Smooth: 凸凹をスムーズに
++++ Icing
+++++ Inflate ブラシ: 垂れてる雫の膨張
+++++ Grab ブラシ: 内側を引っ張る
+++++ Draw ブラシ: 表面を凸凹に
+++++ Smooth ブラシ: 凸凹をスムーズに
+++ 1-6: Rendering
++++ ライトの移動
+++++ 明るさの変更
++++ カメラの移動
++++ Viewport Shading に変更: Z
+++++ 右上のボタンの方がわかりやすい
++++ Set Parent To: Ctrl + P
+++++ 子 -> 親の順で複数選択しておく
+++++ Object (Keep Transform)
+++++ Alt + P で解除できる
++++ レンダリングエンジン
+++++ Eevee: Realtime 系にオススメ
+++++ Cycles: Raytraced 系にオススメ
+++ 1-7: Materials
++++ マテリアルの設定: たくさんあるがほとんどのものが触ることはない
+++++ Base Color: ベースの色
+++++ Roguhness: 反射の粗さ
+++++ Subsurface: 表面化錯乱?
+++++ Subsurface Radiuis: 錯乱半径
++++ ビュー分割: 境界線で右クリック
++++ Render properties -> Color managements -> View transform -> False Color
+++++ サーモグラフィみたいになる
++++ Compositing
+++++ レンダリング後の処理を書ける
+++++ Use Nodes にチェックが入っていないとブロックが見えない
+++++ Node 追加: Shift + A
++++++ Denoise: Filter -> Denoise
+++++++ Render Layers.Noisy Image -> Denoise.Image
+++++++ Render Layers.Denoising Normal -> Denoise.Normal
+++++++ Render Layers.Denoising Albedo -> Denoise.Albedo
+++++++ Denoise.Image -> Composite.Image
++++ Area を最大化: Ctrl + Space
-- Part_2
--- 2-1: Particles
---- Sprinkles は UV Sphere を使う
----- 半分を選択して伸ばす感じで表現
---- スケールの方向も変更する
---- 作った Sprinkle は1つのクラスとして置いておく
----- パーティクルシステムによって Sprinkle インスタンスを大量作成する感じ
---- Particle Properties から追加するとデフォルトのパーティクルが追加される
----- スペースを押すとアニメーションする
----- Emitter と Hair の2種類ある
----- ここでは Hair を選択する
---- Render
----- Render As -> Object
----- Object
------ Instance Object -> Sprinkle(さっき作ったやつ)
------ Scale: サイズを変更する
------ Scale Randomness: Scale にランダム性を付与
---- Advanced にチェックを入れる: 向きが一方向なのを改善するため
----- Rotation
------ Orientation Axis -> Normal
------ Randamise: ランダム性を付与
------ Randamize Phase: 横向きにランダム回転する
---- このままだと Icing の裏側にもパーティクルがいる
----- どこにパーティクルを振り掛けるかを定義したい
------ Weight Paint Mode: 重み付け
----- Vertex Groups
------ Density -> Group
---- パーティクル数を調整する
----- Emissions
------ Number: 個数
--- 2-2: Random Materials
---- Shading
----- マテリアルのカラーをランダム化する
------ Shift + A -> Input -> Object Info
------- Object Info.Random -> Material.Base Color: 白黒でランダムになる
------ Shift + A -> Converter -> ColorRamp
------- ColorRamp で5色作る
------- Linear を Constant に変えるとグラーデションから単色になる
---- Particle Properties
----- Render
------ Renader As -> Collection
------- Object から Collection に変えることによって複数の Object からパーティクルを作れる
------ Use Count
------- コレクション内の Object にプライオリティを付けることができる
---- 曲がったやつも作る
----- ループカット: Ctrl + R
---- Sprinkle の原点
----- 右クリック -> Set Origin -> Origin to Geometory
----- オブジェクトの中心に来る
--- 2-3: Texture Painting
---- Texture Paint
----- Texture イメージを新しく作る
------ 2048 x 1024
------- なぜ横長にしたかは、引き伸ばされる場所が出てきてしまうためと思われる
----- Texture が適用されていない場合はカラーコード#f0fになっている
------ Shading で適用する or マテリアルから ImageTexture を適用する
------ うまく適用できると真っ黒になるはず
------ テクスチャペイントはベースカラーをペインティングしていくイメージ
----- N でメニューを表示してベースカラーを設定する
----- X で色2をメイン色に切り替えることができる
----- Texture Mask
------ ペイントにマスクを掛ける
------ New したら Texture Properties から Type を選ぶことができる
------- Texture Properties 側から New して適用されても問題無し
------ Mask Mapping をランダムにすることでランダム性を付与
------ Mask のサイズを変更することもできる
----- 揚げ面を黒 + Overlay で色を濃くしていく
---- UV Editor (補足)
----- UV Unwrap するところ
------ チョコレートの包み紙みたいな状態にするところ
----- トーラスは最初から UV Unwrap されている
--- 2-4: Procedural Displacement
---- Shading
----- Noise Texture を追加する: Shift + A -> Texture -> Noise Texture
------ 白黒の雲のテクスチャを使って凸凹させたい
----- Texture Coordinate を追加する: Shift + A -> Input -> Texture Coordinate
------ [Texture Coordinate.Object] を [Noise Texture.Vendor] に繋げる
----- Noise Texture の Scale をいじってまだら模様にする
----- Displacement を追加する: Shift + A -> Vector -> Displacement
------ [Noise Texture.Fac] を [Displacement.Height] に繋げる
------ [Displacement.displacement] を [Material Output.Displacement] に繋げる
----- メインノードの状態を Node Wrangler で確認すると...
------ 凸凹している!!
------ しかしメッシュのエッジまでは影響していない
----- Material Properties
------ Setting -> Displacement -> Displacement and Bomp
------- Viewport Shading で見るとヤマアラシ化する
----- Displacement のスケールをイジる
------ 0.003 くらいが良い
----- もっと凸凹にするために Noise Texture の Scale をイジる
------ 1500 くらい
---- Node Wrangler
----- ノードがメッシュ上にどのように影響するかをすぐに見れるプラグイン
------ CTrl + Shift + 左クリック
--- 2-5: Final Donut
---- 大きい突起と小さい突起を作る
----- Noise Texture を複製する
------ Texture Coordinate と繋げる
------ スケールを小さめにしてノイズを粗くする
----- MixRGB を追加する: Shift + A -> Color -> MixRGB
------ 細かい Noise Texture と 粗い Noise Texture を MixRGB で繋げて混ぜる
------- Blend Type は Mix ではなく Add を使用する
------ Fac の値が 0 のとき Color1 が使用され、1 のときに Color2 が使用される
----- ColorRamp を追加する: Shift + A -> Converter -> ColorRamp
------ 粗い Noise Texture と繋げる
------ カラーを制御して突起をでかくする
------ ColorRamp はそのまま MixRGB に繋げる
----- 現実世界でのドーナツ突起はダークになりがち
------ Base Color の方にも MixRGB を追加
------ Noise Texture 側の MixRGB の [Output.Color] を Base Color 側の [MixRGB.Fac] に繋げる
------ Color2 はダークな色を設定
------ Blend Type は Overlay
@endmindmap